Container Basics
Overview
Containers are isolated processes. In this Part-1 of Demystify Containers series, you will learn what is a process, how processes achieve the necessary isolation to become a Container, and Image to Container journey.
- What is a process
- How process becomes a container
- Image & container standards
- Image to container journey
- Linux Filesystem, UnionFS, & Mount (Optional read)
- Change Root & Process Privileges (Optional read)
- Conclusion
What is a Process (Primer)
On your computer, applications run within a boundary/wrapper known as Process.
For example, when you click an Application icon - pointer to its .exe - its instructions set are loaded from disk and into system memory as a Process (boundary). This process boundary helps isolate application’s instruction set from other application sets residing in the shared memory. The CPU context switches between different processes (i.e. applications) to execute their instruction sets. Also, each process is associated with a user. Privileges attached to the user are used to scope process’s access to system resources/commands execution.
Diagram below shows how Process concept works. Source Wikipedia - Process (computing)
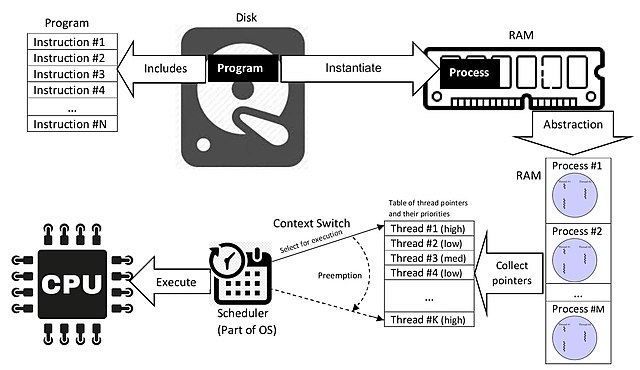
However, the “default” isolation provided by process boundary is not enough for process to become a Container.
In next section, you will learn how processes achieve the necessary isolations to become a container.
Process to Container (Isolations)
In Linux, a Container represents a set of one or more processes - instance of your application running - that are isolated from the rest of the system. Process isolation is empowered by two primary Linux kernel features, Namespaces and control groups (cgroups).
Let’s dig into each of these features.
1/ Namespaces (System resources carved out and isolated)
Namespaces wrap the global system resources in an abstraction which helps carve out instances of system resources (network stack, file system, memory etc.). Each process associated with a namespace can only see and use the resources within that namespace, and descendant namespaces where applicable.
For instance, Linux system (Host here on) has a single namespace called root namespace. By default, processes running on this Host are associated with root namespace and share Host resources within the root namespace.
Diagram below shows root namespace.
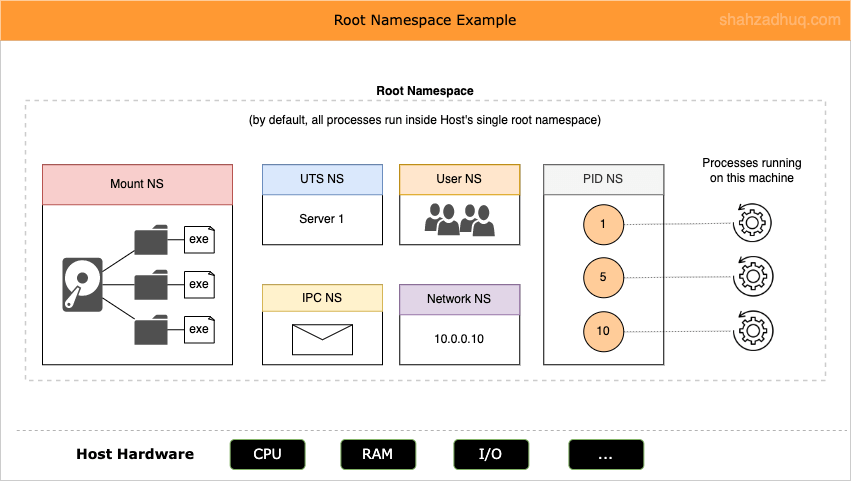
Now for a Container - a process on the Host - to achieve the necessary isolation, following set of namespaces are created to acquire a dedicated and isolated view of the Host resources.
- 0/ cgroups (more on it later).
- 1/ Network: isolated instance of network stack; Network devices, IP Table, ports etc.
- 2/ Mount: isolate storage (filesystem different than the host system) inside the Container.
- 3/ IPC (inter process communication): system resources that allow processes to talk to each other (e.g. POSIX message queue).
- 4/ PID: provides processes with an independent set of process IDs (PIDs) from other namespaces Process ID
- 5/ User: User and group IDs
- 6/ UTS: helps isolate the Hostname of the computer that the process sees. Meaning two different processes in different UTS namespace can have different hostnames while running on the same host computer.
In short, a running Container is a collection of namespaces with your application (processes) running inside them.
[Tip]: It’s recommended to host single process per Container.
But how do you handle the noisy neighbor problem, curb a single Container from hogging all of the Host’s resources? Enter cgroups, discussed next.
2/ cgroups (monitors and enforces Host resource consumption limits)
cgroups help 1/ limit, 2/ account for (i.e. monitor), and 3/ isolate host resource usages (CPU, memory, disk, I/O, network etc.) for a collection of processes. cgroups gives you fine‑grained control to enforce user defined limits on Host resource consumption by the isolated process.
Commonly, cgroups align to the boundary of a Container where a single Container could have one or more processes running inside it.
Putting it all together, combination of namespaces abstraction and cgroups are the core building blocks for statement, “Containers are isolated processes”. Diagram below shows namespaces and cgroups in action.
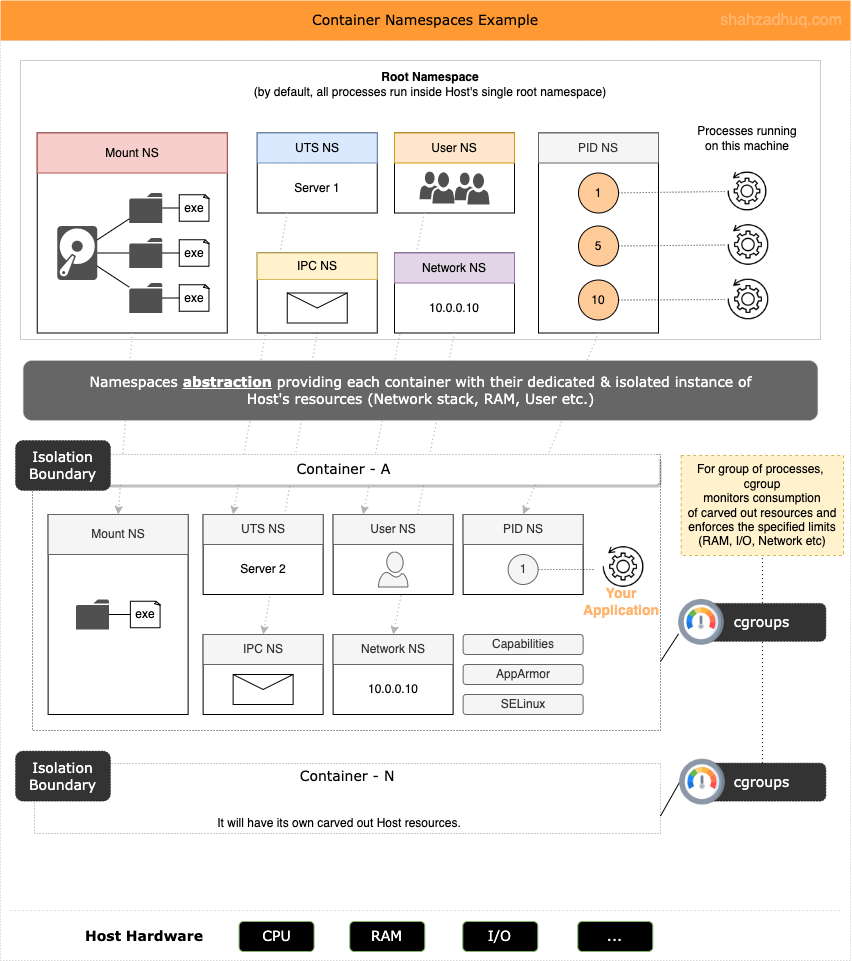
In next section, you will learn about the anatomy of Image and Container.
Image & Container (Blueprint & Standards)
An Image is a blueprint of how to run your application and Container is a running instance of the Image (i.e. your application). You need a standard way to define Image and manage Containers and Open Container Initiative (OCI) is the accepted standards.
Sections below elaborate on each of these.
What is an Image
Let’s understand the anatomy defined by the OCI Image specification.
- Image represents a readonly blueprint of your application. Think of artifacts like operating system files/objects/App files/manifest etc., all packaged together to create a Containers.
- However, the Image itself isn’t a single monolith blob.
- Image has three primary components:
- 1/ Layers - each independent layer is a filesystem representing OS directories, tools, app binaries etc. that will be combined (unified filesystem) to serve as Container’s root filesystem.
- 2/ Manifest file - it describes the independent layers and points to the Config file.
- 3/ Config file - it contains the the instructions about how to run this Image as a container (environment configurations like ENV variables, which ports to expose, how to start the packaged app etc.).
Side Note: Every Image layer gets hashed and the hashed value is used as layer-Id -
digestattribute - in the Manifest file. This ensure you’re downloading the correct layer in a secured manner (locally, Hash gets validated).
Diagram below shows these primary components.

Where are Image Stored
Images are stored in container registry (on-premises or in the cloud like DockerHub). Container Registry has the following constructs: <image-registry-url> / <image-repository-name> / <image-name>. Each Image resides within its repository (e.g. redis, nginx) and with a named/tag that is used to download the Image.
For example
"docker pull redis"
^^ This command reads
# 1/ From container registry at "https://docker.io" (default is DockerHub)
# 2/ look into image repository called "redis"
# 3/ and pull down an image named/tagged "latest" (default name/tag to fetch). [Tip]: In production, avoid pulling Images by name/tag called “latest”. Rather pull specific version like docker pull redis:4.0.0.
- Remember, “latest” is an arbitrary tag like “foo” or “bar”.
- Commonly, image owners may use “latest” to denote the most current version but no guarantees.
Role of Container Engine
Container engine is a general software platform that supports container use. It takes user input, interacts with a container orchestrator, loads the Image file (from a repository), and prepares storage to run the Container. Finally, it calls and hands off the Container to a container runtime to start and manage the container’s deployment.
Role of Container Runtime
Let’s understand the OCI runtime specification.
- Runtime specification outlines how to run a “filesystem bundle” that is unpacked on disk: OCI implementation would download an OCI image, then unpack that image into an OCI runtime filesystem bundle.
- A container runtime is a low-level component of the Container Engine (discussed above) that mounts the container and works with the OS kernel to start and support the containerization process.
- On OS like Red Hat Enterprise Linux, the container runtime would set up namespaces, cgroups, set SELinux policy, set AppArmor rules and so on.
- The most common runtime is runc (used by Docker) and other container runtimes include crun, railcar and Kata Containers.
Image to Container Journey (Peek behind)
With the understanding of how process becomes a Container and how Images work, let’s do a step-by-step walkthrough of Image-to-Container journey (not an exhaustive list).
For illustration purposes, assume you want to run first containerized NGINX.
docker run --name some-nginxWhen you issue the command above, following will happen:
Step-1: NGINX Image will be downloaded from the container registry (default DockerHub).
- Behind the scenes, Image pull is a two step process: 1/ pull down the Manifest file, 2/ pull down the Layers - actual blobs - specified in the Manifest file, 3/ and the Config file.
Step-2: The downloaded Config file and the Layers are extracted onto the disk (container created but not running yet!).
Step-3: When new container is started from this Image, multiple namespaces (Network, Mount, User etc.) are created to achieve process isolation. Here we will focus on Mount namespace.
- A new Mount namespace is created as the root (’/’) filesystem for this container.
- Previously extracted Image layers are re-used. Recall, these are readonly layers.
- On top of these readonly layers, an ephemeral writeable layer is added.
- All these above layers are unified (via UnionFS like aufs/overlay2) into a single root filesystem which is then loaded into this container’s Mount namespace.
- Final product is the Container, who knows nothing of different layers (filesystems), and simply sees it’s own isolated “single” root filesystem with all the files needed to run NGINX.
Upon container termination, related namespaces will be deleted as well. However, previously extracted, readonly Image layers, will continue to live on the disk. If you spin up another container, it will go through the steps above and re-use the previously extracted readonly Image layers.
Diagram below summarizes Image —> Container journey.
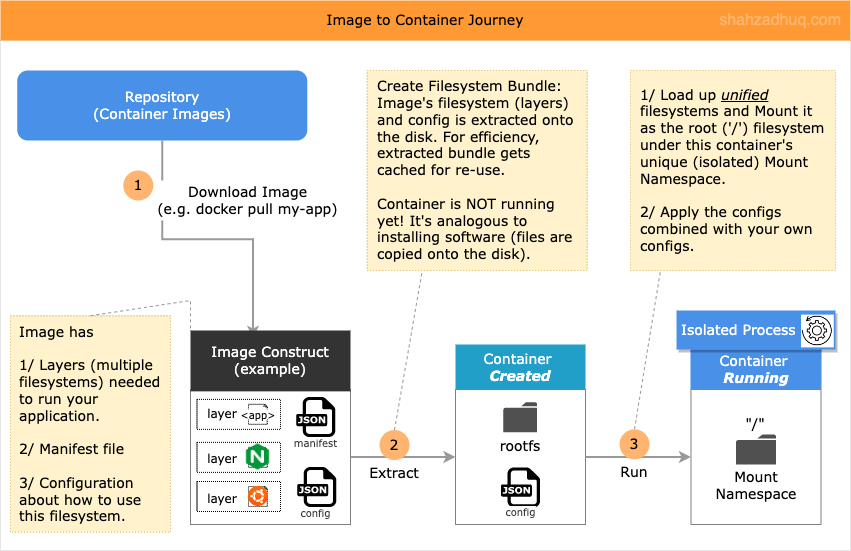
Conclusion
Containers are isolated processes and the necessary isolation is facilitated by two primary Linux kernel features, Namespaces and cgropus. By default system has single root namespace and system resources and hosted processes belong to this root namespace. For container (process on the host), namespaces feature helps carve out isolated view of the system resources (i.e. instances of network stack, filesystem, memory etc.) and the container (associated process) can only see and use resources within its namespace. cgroups feature monitors, tracks, and enforces user defined resource usage limits to ensure no single Container starves out other Containers.
Also, you learned that a container Image represents readonly blueprint of your application and Container is the running instance of the Image. Image isn’t a single blob and consists of three primary components: Layers (actual blobs), Manifest file (pointing to Layers), and Config file (default container settings). Upon starting a Container, Image’s readonly layers and an ad-hoc addition of an ephemeral writeable layers, are all unified (via Linux Union filesystem) and Mounted (namespace) as an isolated single root file system for the Container (i.e. running instance of your application).
Appendix
Filesystem, UnionFS, & Mount (Noteworthy namespaces)
In addition to Namespaces and cgroups Linux features, following three play pivotal role to make the Image —> Container journey possible.
- Filesystem
- It’s Linux operating system layer that handles data management of the storage (directory structure, files, folders etc.).
- Linux directory structure starts at the top, root (
/) directory.
- UnionFS
- Its a filesystem service for Linux which implements a union mount for other file systems.
- It allows files and directories of separate file systems to be transparently overlaid, forming a single coherent file system.
- This gives you the capability to merge multiple filesystems together (i.e. filesystem from each Image layer merged into single root filesystem for the container).
- Advance multi-layered unification filesystem (aufs) and
overlay2are most commonly used Union filesystems.
- Mount
- In Linux, mounting is the process of attaching an additional filesystem on top of the currently accessible filesystem on the computer.
- One of the modern mount types is known as union filesystem, aufs.
Change Root & Process Privileges
Container concepts are built on the shoulder of these old giants. You don’t have to understand them but informative to be aware of them.
1/ Unix has mechanism called Change Root (chroot) directory.
- It changes path to a specified directory which becomes “root” directory for a given process.
- Now instead of seeing the entire Host’s filesystem, process would only see subset; relative to it’s New (chroot) root directory.
- Its one way to help isolate part of the file system from a process and each process can have its own root directory.
- note: “chroot” is not the same thing as Mount namespace.
2/ Process Capabilities (i.e. permission check)
- Its a way to control process’s privileges.
- In Unix, processes used to have privilege categories
- 2A/ privileged
- A process whose effective user ID (UID) is ‘0’,
superuserorroot. - These processes bypass all kernel permissions checks.
- A process whose effective user ID (UID) is ‘0’,
- 2B/ unprivileged
- A process whose user ID is non-zero.
- These processes are subject to full permission checking based on process’s credentials
- 2A/ privileged
- With Linux Kernel 2.2, privileges traditionally associated with superuser got divided into distinct units called
capabilities - Capabilities can be thought of series of individual permissions that can be independently enabled/disabled.
- Example: ability for the process to bind to specific port below 1024 and not anything else.
- Both Security-Enhanced (SE) Linux and AppArmor modules gives you additional means to control process’s capabilities (e.g. network access, permissions to read/write to filesystem etc.).
- Through these
capabilitiesfeature, you can isolate what exactly a process (i.e. container’s access) can/cannot do on a single host sharing resources with other processes.
3/ In 2006, Google did additional work to advance the existing container concept and created “Process Containers” (later nomenclature changed to cgroups).